 An overview of the proposed AERO
An overview of the proposed AEROAbstract
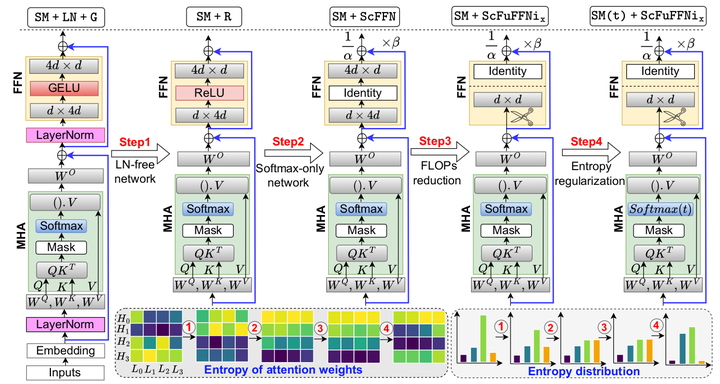
The pervasiveness of proprietary language models has raised privacy concerns for users' sensitive data, emphasizing the need for private inference (PI), where inference is performed directly on encrypted inputs. However, current PI methods face prohibitively higher communication and latency overheads, primarily due to nonlinear operations. In this paper, we present a comprehensive analysis to understand the role of nonlinearities in transformer-based decoder-only language models. We introduce AERO, a four-step architectural optimization framework that refines the existing LLM architecture for efficient PI by systematically removing nonlinearities such as LayerNorm and GELU and reducing FLOPs counts. For the first time, we propose a Softmax-only architecture with significantly fewer FLOPs tailored for efficient PI. Furthermore, we devise a novel entropy regularization technique to improve the performance of Softmax-only models. AERO achieves up to 4.23x communication and 1.94x latency reduction. We validate the effectiveness of AERO by benchmarking it against the state-of-the-art.
Nandan Kumar Jha
PhD student at NYU CCS
My research goal is to enable near-real-time inference on encrypted data by co-designing deep neural networks and cryptographic primitives.