ReLU's Revival: On the Entropic Overload in Normalization-Free Large Language Models
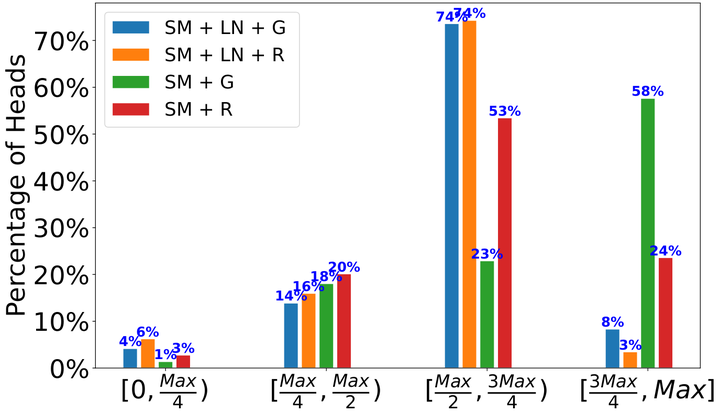 Entropy Distribution Across Attention Heads in GPT-2 Baseline vs. Normalization-Free Models
Entropy Distribution Across Attention Heads in GPT-2 Baseline vs. Normalization-Free ModelsAbstract
LayerNorm is a critical component in modern large language models (LLMs) for stabilizing training and ensuring smooth optimization. However, it introduces significant challenges in mechanistic interpretability, outlier feature suppression, faithful signal propagation, and computational and communication complexity of private inference. This work explores desirable activation functions in normalization-free decoder-only LLMs. Contrary to the conventional preference for the GELU in transformer-based models, our empirical findings demonstrate an opposite trend—ReLU significantly outperforms GELU in LayerNorm-free models, leading to an {\bf 8.2%} perplexity improvement. We discover a key issue with GELU, where early layers experience entropic overload, leading to the under-utilization of the representational capacity of attention heads. This highlights that smoother activations like GELU are {\em ill-suited} for LayerNorm-free architectures, whereas ReLU’s geometrical properties—specialization in input space and intra-class selectivity—lead to improved learning dynamics and better information retention in the absence of LayerNorm. This study offers key insights for optimizing transformer architectures where LayerNorm introduces significant challenges.
Nandan Kumar Jha
PhD student at NYU CCS
My research goal is to enable near-real-time inference on encrypted data by co-designing deep neural networks and cryptographic primitives.